Democratizing Participation in AI in Education
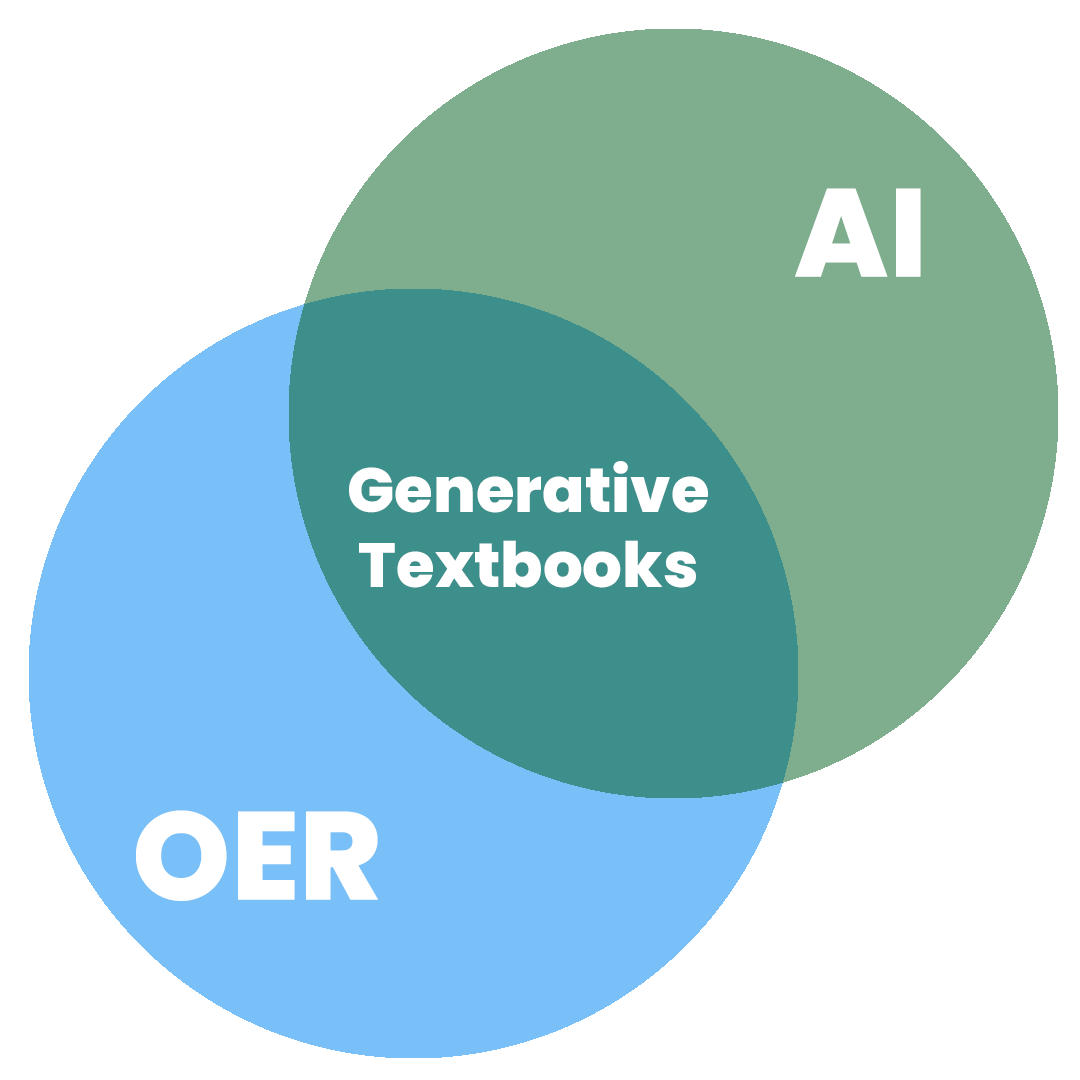
tl;dr – Go play around with generativetextbooks.org and let me know what you think. Earlier this year I began prototyping an open source tool for learning with AI in order to explore ways generative AI and OER could intersect. I’m specifically interested in trying to combine the technical power of generative AI with the participatory … Read more
You must be logged in to post a comment.