Watching Mike’s screencast of the rewiki prototype lead me down memory lane to a tool we built back in the day called Send2Wiki. Here’s a summary from the extensions page at Mediawiki:
- Provides a bookmarklet that makes it easy to send web pages to a wiki.
- Converts web page HTML to wiki format (using html2wiki by David J. Iberri).
- Strips chrome from web pages during the conversion process.
- Displays information about sent articles in the MediaWiki footer.
- Optionally translates web page to another language (using Google’s Language Tools).
- Preserves links by converting relative links to absolute ones.
- Autodetects license information such as Creative Commons and GFDL licenses.
- Lets the user specify a license for the the new wiki page.
- Sends PDFs to the wiki by first converting them to HTML (using PDFTOHTML based on xpdf 2.02 by Derek Noonburg).
- Creates didilies describing the conversion.
Basically, you setup the extension on your Mediawiki and then installed the bookmarklet in your browser. Then you could push the content from any page you’re looking at into your Mediawiki with the click of a button and a few options:
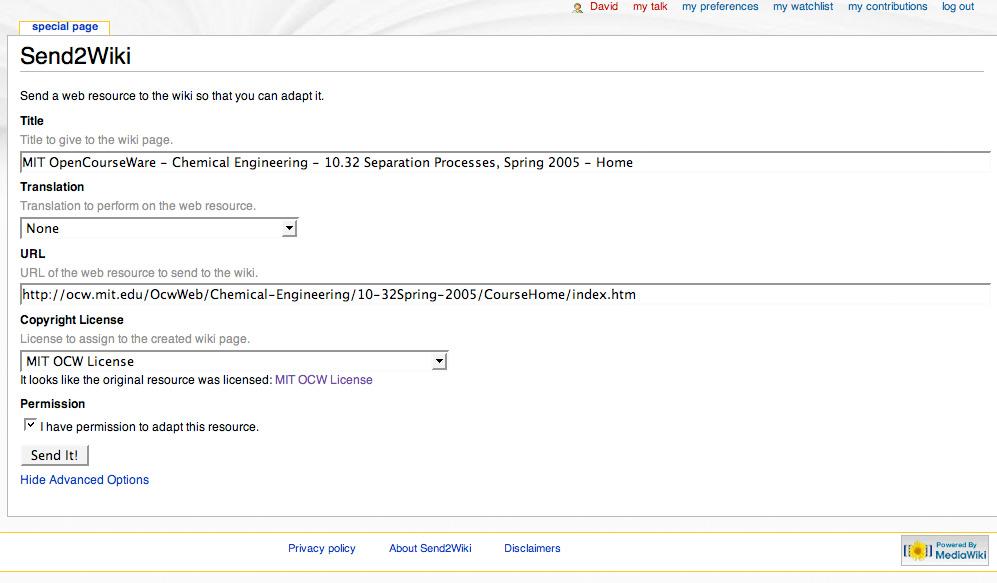
It looks like Mike’s rewiki work is drifting this direction. Maybe someone will get some benefit / reuse out of this old code after all!
That last bullet reminds me of my favorite tool the old COSL team ever built – scrumdidilyupmtious. Inspired by the social bookmarking tool delicious, this was a social relationship-mapping tool. Instead of helping you bookmark a single site, it helped you capture relationships between two sites. It was implemented as a browser extension and server:
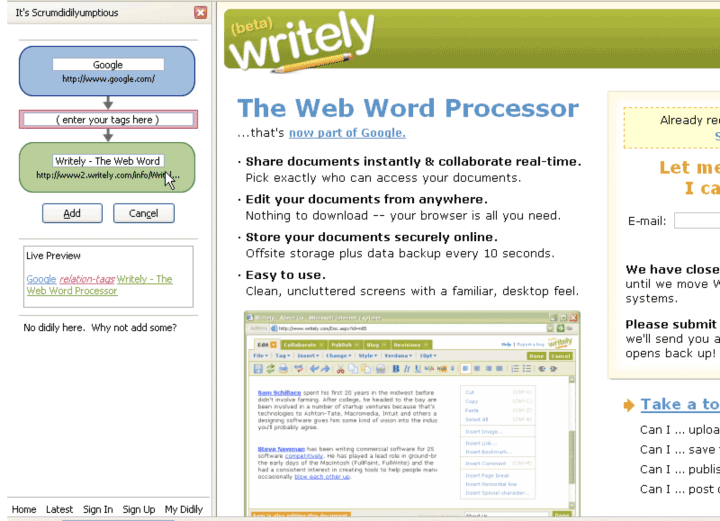
In the case above, you would just type “owns” or “purchased” in the pink box and then hit save. You could then visit the didily site and see “google.com owns writely.com” and all the other relationships you had expressed. More interestingly, you could search the site for a specific URL and get back all the relationships expressed about the URL by everyone, with results coming as RSS, RDF, or HTML.
Ah, we did some cool things back in the day… I still think both these ideas have legs. Hopefully some of it will prove useful!
Awesome! Thanks for these examples. I’ll check out the MediaWiki extension.
One difference might be that this activity gets logged (ok, *will* get logged) to a central place, so that you can see who re-wiki’d your pieces. I’m hoping this will encourage people to share their content because they’ll get props for it (works on Tumblr, right?) but we’ll see. We should pool some of this older stuff though — hopefully people are going to start to see the difference some long overdue tools could make.
That’s why the old system was hooked up to didily – whenever you used send2wiki it created a relationship in didly of the form “[new url on your wiki] is a version of [original url somewhere else].” Rather than build that directly into send2wiki, we separated it out so that other tools could use the “relationship service.” However, since we got basically no adoption, it’s not simple to argue that we made the right choice!
Oh! I didn’t get that you could feed it automatically that way! Is it completely gone? I’d love to not have to write this second part (and actually was considering piggybacking on a bookmarking engine).